Architecting a Fair Marketplace for Decentralized AI
Pnyx is building foundational tools for decentralized AI, starting with a standardized evaluation framework that treats LLMs as black boxes and focuses on outcomes rather than model provenance.
Introduction
The world of Large Language Models (LLMs) is expanding at an incredible pace. Yet, this rapid growth has created a fragmented and often opaque ecosystem. With countless models, architectures, and fine-tuning methods, how can we objectively measure their performance? Centralized services offer partial solutions, but they often introduce new layers of complexity and control, falling short of the open, permissionless ethos that drives true innovation12.
The challenges are clear:
- Diversity of implementations: How do you compare the wide variety of models?
- Performance variability: Why do two seemingly identical models produce different results?
- Lack of transparency: How can we trust the claims of model providers without a neutral evaluation standard?
- LLM Drift: How to detect and mitigate changes in model behavior over time?3
The principle of "do not trust, verify" is more relevant than ever. What we need is a standardized, decentralized, and open framework to level the playing field, and blockchain technology can help us with some of these challenges.
We are Pnyx, a team dedicated to building the foundational tools for decentralized AI. In this inaugural blog post, we will introduce a pioneering approach to the evaluation problem. We will explore:
- Pocket Network as the Decentralized Layer: How Pocket Network's infrastructure provides the perfect backbone for this new paradigm.
- The LLM Black Box: Why evaluating models in a decentralized network is a unique and complex challenge.
- The Pnyx-ML-Testbench: Our open-source framework designed to bring transparency and standardization to LLM evaluation.
- A New Leaderboard Paradigm: How we turn raw data into actionable insights, fostering a competitive and merit-based ecosystem.
Join us as we unpack the future of decentralized AI, starting with the tools that will make it possible.
Pocket Network: The Decentralized Backbone for AI Inference
Pocket Network (POKT) is a decentralized protocol that enables applications to access open data and services without relying on centralized intermediaries. At its core, POKT provides a Remote Procedure Call (RPC) infrastructure, currently mostly focused on blockchain data. This means developers can send a request (for example, "what's the balance of this wallet?") and get a reliable answer from a distributed pool of independent supplier node operators.
Instead of relying on centralized providers, POKT spreads the workload across thousands of suppliers, each incentivized through crypto-economic mechanisms. This makes the network resilient, censorship-resistant, and cost-effective.
One of the protocol's strengths lies in the standardization of API calls and the verification of the response origin. POKT supports the JSON-RPC protocol (among others), a widely accepted format in the blockchain ecosystem and the one used by LLM providers.
Why does this matter for AI? Because the same philosophy—standard interfaces over decentralized infrastructure—is directly applicable to how we deploy and evaluate Large Language Models (LLMs).
The LLM Black Box: A Challenge for Decentralized AI
Generative AI, and in particular LLMs, have become one of the most transformative technologies of our time. These models can process natural language and generate coherent, contextually relevant responses.
While LLMs are powerful, they are also fragmented. Specifically, open-source and proprietary providers release dozens of variations: different architectures, model sizes, fine-tunes, quantizations45, and deployment strategies. In a decentralized network like POKT, where anyone can deploy an LLM endpoint, this leads to an immediate challenge:
Two supplier nodes might both claim to run "Llama-3," yet one might be a 70B parameter model in full precision while another could be a compressed 8B variant. Both are technically valid, but their outputs and quality differ drastically. Moreover, two supplier nodes running the same Llama-3 70B model can produce different outputs depending on their quantization (8-bit, 4-bit, etc.), fine-tuning, or LoRA configurations. In the most extreme case, two supplier nodes running identical models can have different outputs (from the client's perspective) due to the non-deterministic nature of how LLMs are served.6
This complexity makes it nearly impossible to enforce strict model identity rules in a permissionless system (without prohibitive overhead costs). As a result, the network must treat LLMs as black boxes. In the end, what matters is not which exact model weights a supplier node is running, but how well its outputs perform against standardized tasks.
This introduces the black box problem: unlike traditional software, where you can inspect the source code to validate compliance, in a decentralized setting you can only evaluate the models through their responses. In practice, this means focusing on observable behavior rather than internal details.
But evaluating behavior is not trivial. Traditional metrics have limitations:
Exact-match scoring is the most straightforward method. It performs a character-by-character comparison between the model's output and a predefined correct answer.
- Pros: It's simple and works well for fact-based questions or multiple-choice scenarios where the expected answer is precise.
- Cons: This approach is very rigid and tends to over-penalize models. Natural language is flexible, and there are many ways to phrase a correct answer. An otherwise perfect response might be marked as incorrect due to a minor difference in wording or punctuation.
Log probability scoring (logprobs) offers a more nuanced approach. Instead of just checking the final output, it measures how confident a model was in generating the correct answer versus incorrect ones.
- Pros: This method avoids the rigidity of exact-match by focusing on the model's internal probabilities, simplifying the evaluation process.
- Cons: Its biggest drawback is that access to logprobs is often restricted, especially with proprietary black box models. Furthermore, this method is not well-suited for open-ended, creative tasks and is incompatible with modern agent-based models that use reasoning techniques like Chain-of-Thought.
While these methods provide a solid foundation, their limitations reveal a critical need for more sophisticated evaluation techniques. The team at Pnyx is already cooking up a new measurement method designed for the complexities of decentralized AI. Stay tuned, we will be releasing some exciting news in the near future.
In short, measuring the quality of LLMs in a way that is fair, reproducible, and scalable is one of the central bottlenecks for bringing these models into a decentralized, permissionless network like POKT.
The Solution: Pnyx-ML-Testbench
The Pnyx-ML-Testbench addresses this challenge by providing a standardized, off-chain evaluation framework for LLMs deployed in the Pocket Network.
Instead of focusing on what model is behind a supplier, the Pnyx-ML-Testbench focuses on outcomes. Every participating supplier is tested through a set of benchmark tasks derived from widely recognized evaluation frameworks (like lm-eval-harness78 and open leaderboards9). These benchmarks act as a neutral ground: no matter which model or variation is used, the evaluation process is the same.
Moreover, the modular design of the Pnyx-ML-Testbench, as illustrated in the figure below, allows for easy integration of new benchmarks and metrics. This ensures that the testbench can evolve alongside advancements in AI evaluation techniques, maintaining its relevance and effectiveness over time.
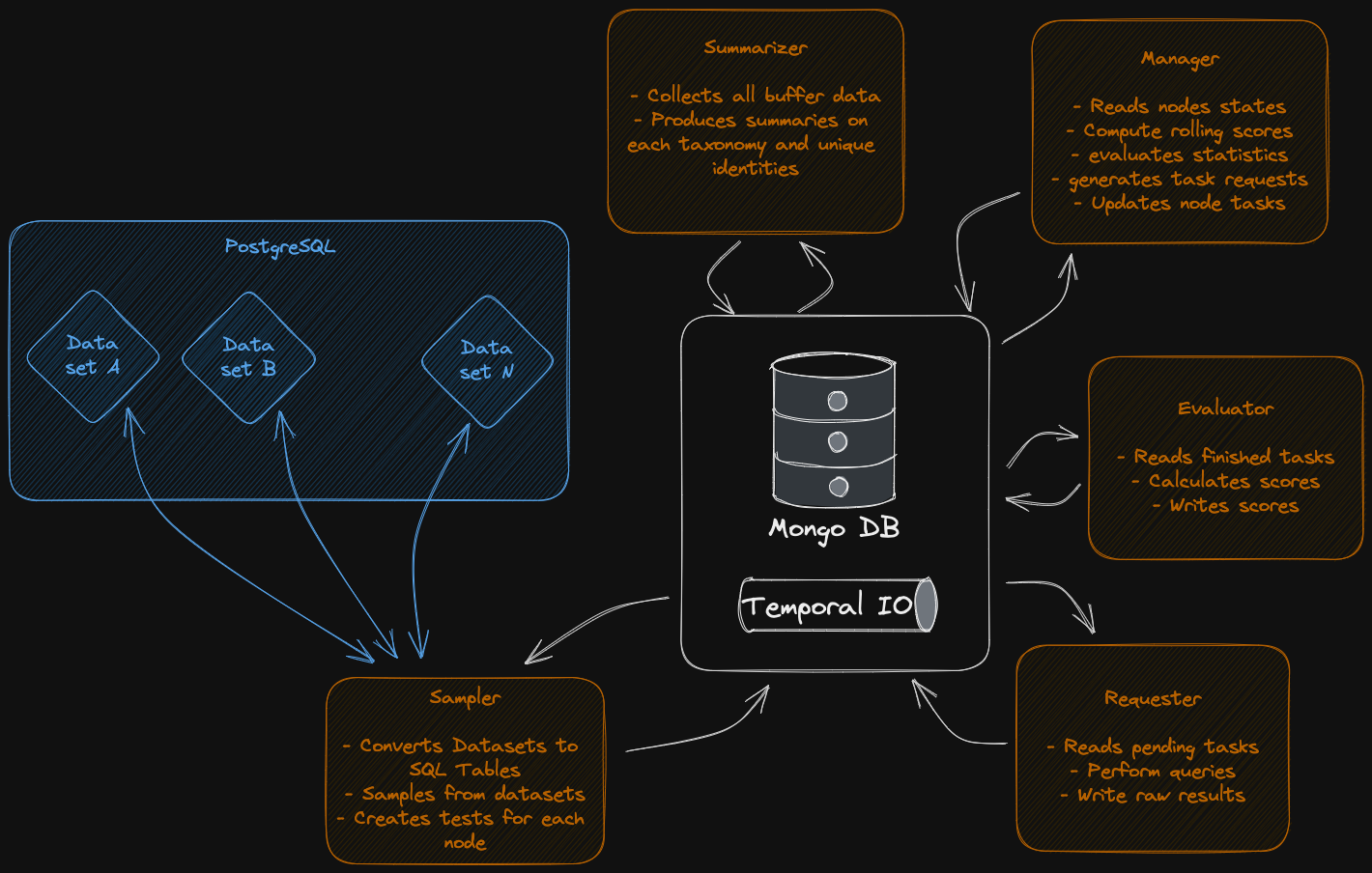
This approach brings several advantages:
- Standardization: All models are measured against the same datasets and metrics, ensuring comparability.
- Transparency: Results are made publicly available, allowing developers, researchers, and investors to see performance in real time.
- Scalability: As the network grows, the evaluation framework can automatically track more suppliers and update results continuously.
- Flexibility: Beyond existing metrics like exact-match or logprobs, the system leaves space to integrate new techniques for evaluating free-form generation, such as semantic similarity.
In essence, the Pnyx-ML-Testbench makes it possible to create a common language of quality in a decentralized AI marketplace.
For those enthusiasts who want to dive deeper, the full source code and methodology are open-sourced and available for review on GitHub and more technical details can be found in our series of reports.
The Leaderboard: Fostering Competition and Excellence
All the data generated by the Pnyx-ML-Testbench is aggregated into a Leaderboard. This functions as a live, transparent scoreboard of how different models (or rather, different supplier nodes) are performing in the network.
Unlike static leaderboards, which only reflect centralized experiments, this leaderboard reflects real-world performance under real network conditions. This makes it not just an academic exercise, but a practical tool for:
- Developers, who can choose the best-performing supplier nodes for their applications.
- Investors, who gain visibility into which models are proving reliable and valuable.
- Supplier Node Operators, who are incentivized to improve their offerings to climb the rankings.
From Dataset to Skills
One of the most exciting directions is moving beyond raw benchmark scores toward a skill-based taxonomy. Instead of only reporting aggregate percentages, we believe that a leaderboard should highlight strengths across categories like reasoning, summarization, coding, or factual knowledge.
This makes a leaderboard more meaningful for end users. Instead of asking, "which model scores highest on a benchmark like MMLU?", they can look at the underlying skills. A single benchmark is often composed of multiple subtasks that measure different abilities, such as reasoning, common sense, or mathematics. This allows users to ask the far more practical question: "which model is best for the skill I actually need?" For a decentralized network, this creates the conditions for specialization, where supplier node operators can focus on niche skills and still find market demand.
We are excited to announce that this skill-based view is now live! You can explore it directly on the Leaderboard or dive into the detailed breakdown for each model, such as this example for GPT-5-Mini.
Conclusion
The Pnyx-ML-Testbench represents a fundamental shift in how we approach AI inference and its evaluation. By treating LLMs as black boxes and focusing on standardized evaluation rather than model provenance, we've created a framework that embraces the inherent diversity of decentralized networks while maintaining quality standards.
This approach isn't just theoretical—it's already delivering results. The testbench successfully replicated established benchmarks like the Hugging Face Open LLM Leaderboard with significantly fewer samples, proving that efficient evaluation is possible at scale. More importantly, it does so while supporting the concurrent testing of multiple supplier nodes, something traditional frameworks weren't designed to handle.
But perhaps the most exciting aspect is what this enables: a truly decentralized AI marketplace where competition is based on performance, not pedigree. As Jorge Luis Borges reminds us, "Thinking, analyzing, inventing are not anomalous acts, they are the normal breathing of intelligence." The Pnyx-ML-Testbench ensures that this breathing remains free and open, allowing innovation to flourish without the constraints of centralized gatekeepers.
As the AI landscape continues to evolve, so too will our evaluation methods. The modular design of the testbench means it can adapt to new benchmarks, new metrics, and new ways of measuring what makes an AI system truly valuable. This isn't just about building better infrastructure—it's about democratizing access to the intelligence that will shape our future.
The decentralized AI revolution has begun, and with tools like the Pnyx-ML-Testbench, we're not just participants—we're the architects of a more open, competitive, and innovative tomorrow.
References
-
Chen, L. et al. (2023). How is ChatGPT's behavior changing over time? (No. arXiv:2307.09009). arXiv. http://arxiv.org/abs/2307.09009 ↩
-
Frantar, E. et al. (2023). GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers (No. arXiv:2210.17323). arXiv. https://doi.org/10.48550/arXiv.2210.17323 ↩
-
Lin, J. et al. (2024). AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration (No. arXiv:2306.00978). arXiv. https://doi.org/10.48550/arXiv.2306.00978 ↩
-
https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/ ↩
-
Sutawika, L. et al. (2025). EleutherAI/lm-evaluation-harness: V0.4.9.1 [Computer software]. Zenodo. https://doi.org/10.5281/zenodo.16737642 ↩
-
Liang, P. et al. (2023). Holistic Evaluation of Language Models (No. arXiv:2211.09110). arXiv. https://doi.org/10.48550/arXiv.2211.09110 ↩
-
Fourrier, C., Habib, N., Lozovskaya, A., Szafer, K., & Wolf, T. (2024). Open LLM Leaderboard v2. Hugging Face. https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard ↩